Historie vyhledávání
Historie a vývoj fulltextového vyhledávání v bodech:
- Seznam.cz je česká firma založená v roce 1996 jako klasický internetový katalog s několika kategoriemi. Kromě katalogu internetových stránek jsme tehdy nabízeli i přehled novinek na českém internetu a žebříček nejlepších českých internetových stránek.
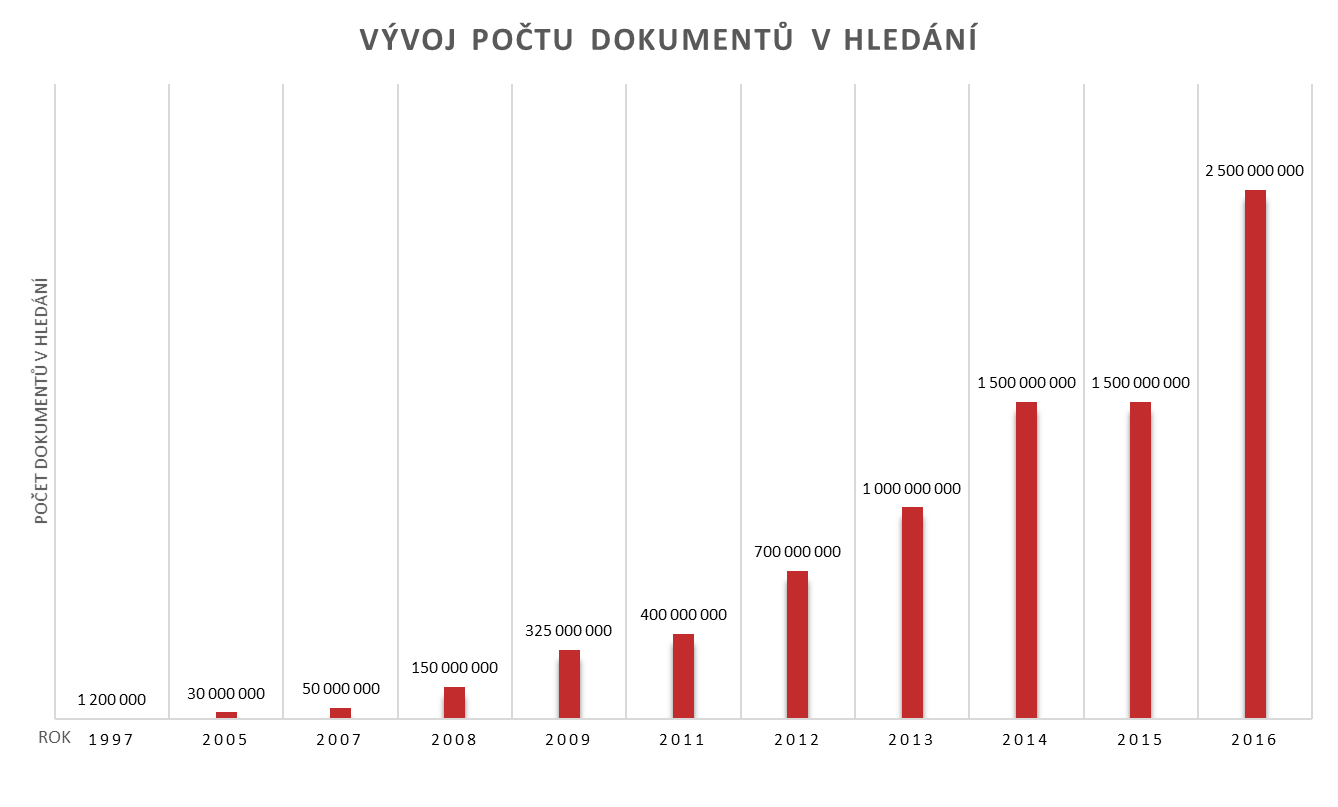
- V roce 1997 jsme spustili své vlastní fulltextové vyhledávání, které indexovalo 1,2 milionů stránek, pod názvem Kompas. Kompas uživatelům poprvé umožnil zadávat dotazy s českou diakritikou.
- Po pár letech rozšiřování služeb je pro fulltextové vyhledávání zajímavý rok 2002, kdy jsme zkusili využívat služeb společnosti Google. Po krátké zkoušce jsme se ale rozhodli službu nevyužívat.
 Vyzkoušeli jsme několik možností vyhledávání: Empyreum, Google, poté Jyxo. Nakonec jsme se ale v roce 2005 rozhodli pro vlastní vyhledávání, o jehož vývoj a spuštění se postaral čtyřčlenný tým. Vyhledávání využívalo databázi 30 milionů dokumentů jen v rámci českých webů a běželo na 14 serverech.
Vyzkoušeli jsme několik možností vyhledávání: Empyreum, Google, poté Jyxo. Nakonec jsme se ale v roce 2005 rozhodli pro vlastní vyhledávání, o jehož vývoj a spuštění se postaral čtyřčlenný tým. Vyhledávání využívalo databázi 30 milionů dokumentů jen v rámci českých webů a běželo na 14 serverech.
- Rychlejší a lepší indexaci pomohla v roce 2007 nová verze robota SeznamBot/2.0, která již fungovala na několika MySQL databázích. Zároveň se tento rok stala architektura fulltextu škálovatelnou.
- V roce 2008 jsme zavedli možnost přizpůsobení výsledků vyhledávání (SERP) potřebám zrakově postižených. Začali jsme také do hledání zpracovávat jiné formáty než klasické HTML stránky (například PDF, DOC apod.).
- Od roku 2009 jsme pro sekci hledání „ve
 světě“ začali využívat výsledků vyhledávače Bing společnosti Microsoft. Zároveň se díky lepšímu způsobu pochopení dotazů mnohonásobně zvýšila relevance výsledků. Také díky tomu se nám podařilo umístit na prvním místě v kategorii Vyhledávače a databáze soutěže Křišťálová Lupa. V tomto roce byla také spuštěna nová verze tzv. screenshotátoru, který ke stránkám nalezeným ve vyhledávání dodává obrázky s náhledy.
světě“ začali využívat výsledků vyhledávače Bing společnosti Microsoft. Zároveň se díky lepšímu způsobu pochopení dotazů mnohonásobně zvýšila relevance výsledků. Také díky tomu se nám podařilo umístit na prvním místě v kategorii Vyhledávače a databáze soutěže Křišťálová Lupa. V tomto roce byla také spuštěna nová verze tzv. screenshotátoru, který ke stránkám nalezeným ve vyhledávání dodává obrázky s náhledy.
- S rostoucím počtem prohledávaných dokumentů a rozšiřujícími se funkcemi se zvyšovala i výpočetní náročnost. V roce 2010 mělo celé vyhledávání přes 100 serverů a samotný robot, který je jednou z komponent celého vyhledávání, běžel na desítkách serverů.
 Velikým pokrokem bylo v roce 2011 nasazení nového robota SeznamBot/3.0, který přinesl přechod z několika MySQL databází na technologii Hadoop. Zároveň jsme z celé databáze stažených dokumentů začali dělat výběr těch nejlepších, které je možné zařadit mezi výsledky vyhledávání. Ve stejném roce jsme také testovali technologie společnosti Yandex a spustili jsme beta verzi vyhledávání ve videích. Spustili jsme také speciálně upravené vyhledávání ve volnočasových aktivitách.
Velikým pokrokem bylo v roce 2011 nasazení nového robota SeznamBot/3.0, který přinesl přechod z několika MySQL databází na technologii Hadoop. Zároveň jsme z celé databáze stažených dokumentů začali dělat výběr těch nejlepších, které je možné zařadit mezi výsledky vyhledávání. Ve stejném roce jsme také testovali technologie společnosti Yandex a spustili jsme beta verzi vyhledávání ve videích. Spustili jsme také speciálně upravené vyhledávání ve volnočasových aktivitách.
- Rok 2012 přinesl přechod k rozsáhlejšímu indexování cizojazyčných stránek. Počet prohledávaných dokumentů tak vzrostl ze 400 milionů na 700 milionů (robot sice zná dokumentů mnohem více, ale mezi výsledky se dostanou jen ty nejlepší).
- Uživatelů s tablety a chytrými mobilními telefony rapidně přibývá, proto jsme v roce 2013 spustili responzivní design hledání, který se vydává na základě detekce zařízení. V tomto roce jsme také začali zveřejňovat skokany hledání na Twitteru.
- V roce 2014 jsme začali zobrazovat ve výsledcích hledání mnohem širší náhledy stránek a k nejrelevantnějším přirozeným výsledkům, které vydáváme pro navigační dotazy, jsme nově přidali rychlé odkazy odkazující na dokumenty ze stejné L2 domény. V upoutávkách a našeptávači jsme začali zohledňovat polohu uživatelů a také jsme se pustili do úpravy vzhledu rozložení výsledků z lineárního na maticový. Během testování se však maticový vzhled neosvědčil, proto jsme zůstali u lineárního.
- Rok 2015 přinesl ve vyhledávání spoustu změn. V prvé řadě jsme přestěhovali část web-crawlera do nově vybudované serverovny Kokura, vylepšili jsme indexování HTTPS webů, zlepšili jsme detekci jazyka stránky, spustili jsme Freshbota, který má za úkol navštěvovat stránky a RSS zdroje, kde se objevuje nový zajímavý obsah zejména novinové články. Přešli jsme na novější distribuci Hadoopu na výpočetních clusterech robota, spustili jsme vlastní hledání obrázků a videí. Pomocí aplikace sBrowser jsme umožnili v mobilech či tabletech vyhledávat hlasem a zatočili jsme s webspamem nasazením aktualizace vyhledávání Jalapeňo.
- V roce 2016 jsme pokračovali s bojem spamových webů ve výsledcích hledání nasazením aktualizací Jalapeňo 2.0 a později i Jalapeňo 3.0. Neustále se snažíme dávat uživatelům do hledání kvalitní weby a stránky, o což se postarala další aktualizace, kterou jsme pojmenovali Page Quality. Dále jsme nasadili nový operátor „info:“, pomocí kterého je možné ověřit, zda je URL v indexu. Spustili jsme rychlé stahování a indexování nových videí a nasadili jsme vylepšenou a rychlejší verzi Freshbota Mach II, který obsluhuje 2x více zdrojů než původní Freshbot. Také jsme navýšili velikost databáze robota, díky čemuž jsme mohli zpřesnit plánování návštěv robota na webových stránkách. A když už jsme navýšili databázi robota, navýšili jsme ke konci roku také databázi hledání tzv. index.
Protože chceme, aby u nás uživatelé vždy našli to, co hledají, budeme vyhledávání i nadále rozvíjet a zlepšovat. Vývoj vyhledávání je dlouhá a nikdy nekončící cesta.
Další informace o historii celé firmy Seznam.cz naleznete na stránce O firmě.